Hivatkozott Excel verzio: Excel 2007 Excel 2010 Excel 2016

Több korábbi írásban mutattam érdekes megoldásokat az INDEX függvény segítségével, de most úgy döntöttem, hogy egy külön cikket is szentelek neki, mert megérdemli. Talán egyik Excel függvényről sem lehet kijelenteni, hogy a legszuperebb, de ha megemlékeznék az első 10-ről, abban biztosan benne lenne.
Ebben a cikkben is csak a felszínt kapargatom, és nem is célom egy teljesen kimerítő, mindent bemutató leírás, mégis azt remélem, hogy sokan meglátják a lehetőséget.
INDEX első látásra
Ha elkezdjük gépelni az INDEX függvényt, illetve ha a függvényvarázslóval illesztenénk be, ilyesmiket látunk:

Ez eléggé zavarba ejtő, mert most akkor mi van, melyik micsoda, mitől függ, melyiket válasszuk? Nos, ebben a cikkben csak az első féle szintaktikáról esik szó, a másodikról legfeljebb majd megemlékezem a végén.
Első látásra azt csinálja, hogy az első argumentumként megadott tartományból (tömb), kiválaszthatunk egy elemet a sor és oszlop indexe alapján, és azt adja vissza. Az alábbi ábrán azt látjuk, hogy a B2:G7 tartomány második sorában és harmadik oszlopában lévő értéket címeztük meg, és vissza is kapjuk a 19-et.
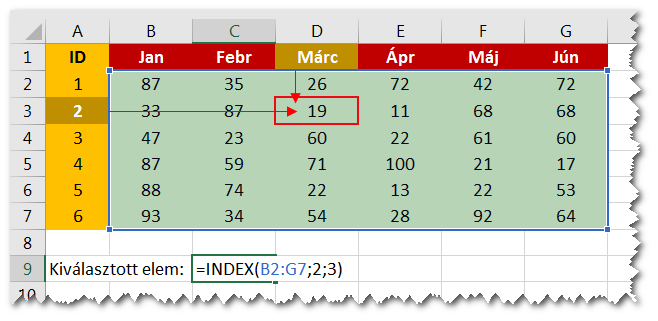
A fenti ábrákon látszik, hogy az oszlopszám argumentum nem kötelező. Nézzük meg először ezt.
INDEX egy dimenziós tömbök (vektorok) esetén
Bár a súgó azt mutatja, hogy a második argumentum a sorszám, ez egy kissé megtévesztő. A valóság az, hogy ha egydimenziós tartományt adunk át az INDEX-nek, akkor a második paraméterben a tartomány elemsorszámát adjuk meg, legyen az függőleges vagy vízszintes tartomány, mindegy. Tehát függőleges tartomány esetén van értelme a sorszám elnevezésnek, de vízszintes tartomány esetén csak az elem sorszámnak van.
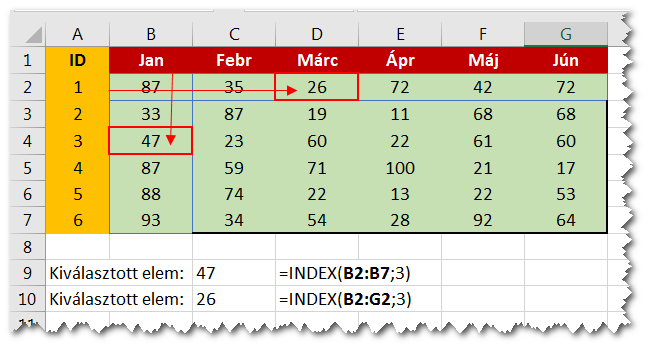
1D és 2D keresések
Az előbbiekben felvázolt módon használhatjuk az INDEX függvényt keresésekhez. Ilyenkor a sor, illetve oszlop indexek lehetnek beágyazott számítások vagy cellahivatkozások eredményei. Ezek közül a leghíresebb az FKERES (VLOOKUP) kiváltására szánt INDEX/HOL.VAN (INDEX(MATCH) páros, ami az FKERES hiányosságait és gyengeségeit kiküszöbölve működik. Erről a mai napig a legolvasottabbak közé tartozó cikkben írtam.
De könnyen belátható, hogy ha egy 2D tartományban a sor és az oszlop index is egy keresés eredménye, akkor máris egy szuper 2D keresőt készítettünk. A következő ábrán a B9, illetve E9 cellákban megadott értékek által meghatározott elemet választjuk ki.
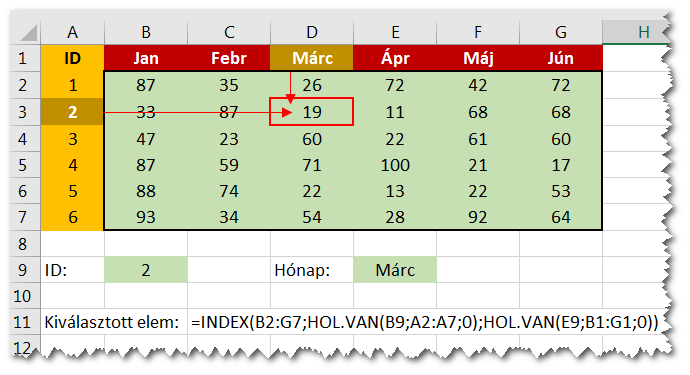
Teljes sor vagy oszlop visszaadása
Na, mostantól kezd izgalmasabbá válni a dolog. Ugyanis az már kevésbé ismert, hogy a megadott tartomány kiválasztott sorát vagy oszlopát is vissza lehet kapni.
Ha a sorszám argumentum helyére nullát írunk, vagy elhagyjuk, de megadjuk az oszlopszámot, akkor a megadott sorszámú, teljes oszlop referenciát kapunk vissza. Ha az oszlop argumentumot nem adjuk meg, de megadjuk a sorszámot, akkor a megadott teljes sor hivatkozását kapjuk.
Teljes sor vagy oszlop lekérés esetén a visszakapott tartomány hivatkozással kezdenünk kell valamit, leggyakrabban valamilyen összesítő függvénnyel (SZUM, ÁTLAG, MAX, MIN, stb.) érjük el, hogy egy darab eredményünk legyen.
Szerintem fantasztikus lehetőség, hogy egy tartományból dinamikusan tudunk kiválasztani egy egész sort vagy oszlopot, ahogy a következő ábra mutatja:
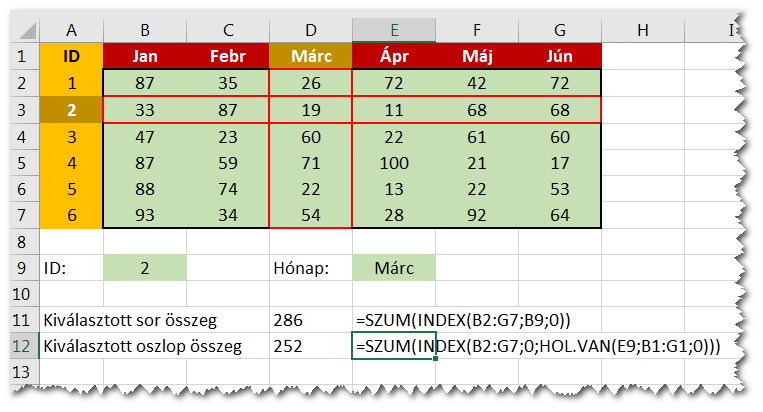
A visszaadott érték hivatkozás (Referencia)
Az első három példában a referenciát kiértékelve a megcímzett cella értékét kaptuk vissza. A teljes sor/oszlop kiválasztás esetén már megtartja a referenciát, ami ugye több cellára vonatkozik, és ezt a referenciát adja át a SZUM függvénynek, ami összegzi a megcímzett cellák tartalmát.
Változó méretű tartomány meghatározása
Gyakori feladat, hogy egy adott bázis cellától kezdődően adjunk meg, vagy mérjünk meg egy tartományt. Klasszikus példa erre a dinamikus névtartomány létrehozása, de egyéb példák is léteznek. Régebben ilyesmire az ELTOLÁS (OFFSET) függvényt használták, de az VOLATILE tulajdonságú. Ez azt jelenti, hogy nem csak akkor számolódik újra, ha valamely argumentuma megváltozik, hanem minden, a munkafüzetet érintő változáskor újra kalkulál. Emiatt helyette az INDEX-es megoldás a „Best Practice”.
Ebben az esetben nagyon furcsának tűnő hivatkozást kell készíteni. Nézzük a következő példát:
=SZUM(A1:INDEX(A:A;4))
A SZUM függvénynek egy olyan tartományi hivatkozást adunk át, ami fixen az A1-ben kezdődik, de a kettőspont után a végcellát az INDEX függvénnyel kerestetjük meg. Ez pedig az A oszlop negyedik cellája. Tehát a képlet így is kinézhetne:
=SZUM(A1:A4)
Az első verzió nagy előnye, hogy ha a végén lévő 4-es helyett egy cellából vesszük, vagy képlettel számoljuk, hogy az A oszlop hányadik cellája legyen az utolsó elem, akkor máris egy dinamikusan változtatható méretű tartománnyal dolgozhatunk.
Az utolsó példában pedig az látható, hogy a DARAB2 függvénnyel megmérjük, hány kitöltött cella van az A oszlopban, és oda tesszük az összegzendő tartomány végét.
=SZUM(A1:INDEX(A:A;DARAB2(A:A)))
További példák találhatók a Változtatható méretű bemeneti tartomány és a Dinamikus névtartomány képlettel tartalmú, korábbi cikkekben.
Vélemény, hozzászólás?
Hozzászólás küldéséhez be kell jelentkezni.