Hivatkozott Excel verzio: Excel 2007 Excel 2010 Excel 2013
Nemrég volt egy kérdés a Fórumban erről, és mivel már sokadszorra jön szembe, arra gondoltam, hogy írok róla.
Szövegből számot konvertálni többféleképpen lehet. Itt az Excel-Bázison is írtam 4 féle megoldást egy korábbi post-ban. De mit tehetünk, ha egyik sem válik be?
A szóköz probléma leírása
Adott valamilyen külső forrás, leggyakrabban valamilyen pénzügyi vállalati szoftver vagy annak modulja, ami text , CSV, vagy Excel formátumban szolgáltat kimenetet. De tapasztalataim szerint a forrás lehet egy weboldal is, ahol un. „nonbreaking”, azaz nem törhető HTML szóközök vannak.
Azt tapasztaljuk, hogy vannak olyan oszlopok, ahol szóköz ezres elválasztóval tagolt számok vannak, de szövegként érzékeli az Excel őket, és sehogy nem boldogulunk a számmá alakítással.
Lehetséges megoldás
Ilyenkor arra kell gyanakodni, hogy az a szóköz valójában nem is szóköz, hanem valami egyéb, szóköznek látszó tárgy. Ha ezt a valamit ki tudnánk szedni a számjegyek közül, lehet, hogy meggyógyul az egész.
Ha nem érdekel, hogy mi az, csak tűnjön el onnan
Próbáld meg alkalmazni a Csere funkciót (Ctrl-H).
- A keresett szöveg legyen ez a valami, ami olyan, mint egy szóköz. Csak másold ki a cellából ezt az egy karaktert, és illeszd be a csere párbeszédbe. (Vagy írd be az ALT-0160 kódot)
- A Csere erre részt pedig hagyd üresen. Ez azt jelenti, hogy azt a valamit cseréli a semmire, azaz kiveszi a cellákból.

Eredményként valószínűleg megkapod a számmá alakított értékeket, és helyreáll a világ rendje.
Ha érdekel, hogy milyen karakter van ott
Ehhez kell minimális háttér ismeret a karakterkódolással kapcsolatban. A szövegeket karakterenként tároljuk úgy, hogy mindegyiknek van egy kódszáma, és valójában a kószámokat tároljuk, és a megjelenítéskor lesz belőle a megfelelő megjeleníthető karakter, vagy vezérlő karakter. Vezérlő karakter lehet például az új sor, vagy sortörés, stb…
Léteznek különböző kódrendszerek, és kódtáblázatok, amelyek tartalmazzák, hogy mely karakternek mi a kódja. Ezek a táblázatok a kódokat 10-es (decimális) és/vagy 16-os (hexadecimális) értékként mutatják. Erről most nem írnék részleteket, csak célirányosan annyit, hogy a szóköz kódja a decimális 32 (hexadecimális 20).
Tehát ha a problémás cellát, vagy csak magát a problémás karaktert kitesszük egy sima text fájlba (Jegyzettömb), akkor már csak egy olyan program kellene, amivel bele tudunk nézni úgy, hogy lássuk a kódokat.
A Total Commander nézőkéje (F3)
A TC szinte mindenkinek fent van a gépén. Ennek az F3-as parancsa a nézőke, azaz a kijelölt fájlt megnyitja, és láthatjuk a tartalmát, ha a TC maga ismeri a formátumát. Egy egyszerű text formátumnál ez alap.
Nézzünk bele abba a text fájlba, amibe kitettem a szóban forgó egy darab karaktert.
- F3 után szöveges nézetben nyitja meg, így még nem látszik semmi
- Válasszuk a Beállítások->Hexa menüpontot! Ezzel átvált Hexadecimális kódnézetre
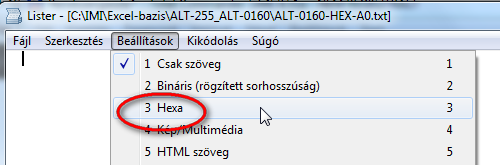
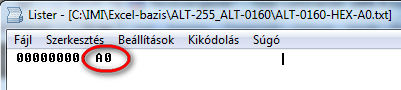
- Most már látjuk a fájl tartalmát karakterkód szinten, és az is látszik, hogy a várt Hexa 20-as helyett az A0 kód látszódik, ami decimálisan a 160, tehát ez bizonyára nem szóköz.
A videóból az is kiderül, hogyan lehet ezt a karaktert szándékosan bevinni, és hogy lehet függvénnyel eltávolítani.
Furcsa szóközök eltávolítása
Vélemény, hozzászólás?
Hozzászólás küldéséhez be kell jelentkezni.