Hivatkozott Excel verzio: Excel 2007 Excel 2010 Excel 2013 Excel 2016
Adott egy cella vagy egy oszlop. Arra vagyunk kíváncsiak, hogy hol van az első nagybetű. Meglehetősen speciális eset, de végül mégis úgy döntöttem, hogy írok róla, mert ebből a megoldásból következően, kisebb módosításokkal más feladatok is megoldhatók.
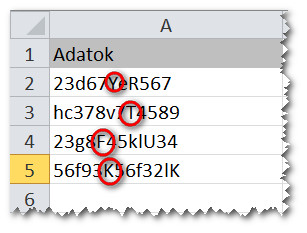
Tehát nem tudjuk előre, hogy melyik nagybetű, és nem tudjuk, hogy hol. Sőt, azt sem tudjuk, hogy van-e nagybetű egyáltalán. Melyik nagybetűt keressük?
És van még egy probléma: Hogyan teszünk különbséget nagybetű és kisbetű között?
A keresőfüggvény
Ha nem egy, hanem az összes nagybetűt keressük, az megoldás lehetne. A kereséshez olyan függvényre van szükség, ami megkülönbözteti a kis és nagybetűket.
Ez a függvény a SZÖVEG.TALÁL. Angol neve FIND.
=SZÖVEG.TALÁL(mit_keres; miben_keresi; [honnan_keresi])
Az utolsó argumentum nem kötelező. Ha elhagyjuk, akkor az elejétől keres. Ha megtalálja a keresett szöveget, akkor megadja a pozícióját. Ha nem találja meg, akkor hibát ad.
Hogy használjuk a mi problémánkhoz
=MIN(HAHIBA(SZÖVEG.TALÁL({"A";"Á";"B";"C";"D";"E";"É";"F";"G";"H";"I";"Í";"J";"K";"L";"M";"N";"O";"Ó";"Ö";"Ő";"P";"Q";"R";"S";"T";"U";"Ú";"Ü";"Ű";"V";" W";"X";"Y";"Z"};C3);100))
Hogyan működik?
A példában a C3 cellában van az a szöveg, amiben keressük az első nagybetűt. A SZÖVEG.TALÁL függvény keresi az összes nagybetűt, amelyek egy tömbben vannak felsorolva, a C3 cellában.
Ennek a keresésnek az eredménye egy olyan tömb, ahol hiba lesz azoknál a betűknél, amelyek nincsenek benne, és a pozíció száma, ha benne van.

Azt látjuk, hogy az „R” helyén van egy 8-as, az „Y” helyén pedig van egy 6-os. Tehát a C3 8.-dik karaktere „R” és a 6.-dik karaktere „Y”.
A HAHIBA (IFERROR) függvény az #ÉRTÉK üzeneteket cseréli egy nagy számra.
Lényeges, hogy ez a szám nagyobb legyen a C3-ban lévő szöveg hosszánál. ha egy egész oszlopra használjuk a képletet, akkor az oszlopban előfordulható leghoszabb szöveg hosszánál legyen nagyobb. Itt most Én 100-at választottam.
Ezek után az előbbi tömb így néz ki:
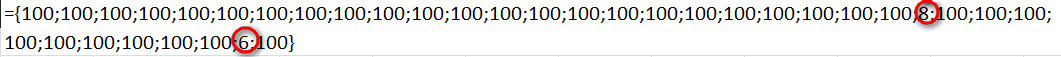
A hibák helyén ott a 100-as érték.
Utolsó lépésként a MIN függvénnyel kivesszük ennek a tömbnek a legkisebb értékét, ami tehát megadja az első nagybetű pozícióját. Jelen példában ez a 6-os lesz.
Mi van, ha a betű kell, és nem a pozíciója?
Mivel a pozíciója már megvan, csak ki kell vennünk az eredeti szövegből az adott pozícióból 1 db karaktert. Ez a KÖZÉP (MID) függvénnyel tehető meg. A képlet ebben az esetben így alakul:
=KÖZÉP(A2;MIN(HAHIBA(SZÖVEG.TALÁL({"A";"Á";"B";"C";"D";"E";"É";"F";"G";"H";"I";"Í";"J";"K";"L";"M";"N";"O";"Ó";"Ö";"Ő";"P";"Q";"R";"S";"T";"U";"Ú";"Ü";"Ű";"V";" W";"X";"Y";"Z"};A2);100));1)
Mi van akkor, ha nincs nagybetű?
Akkor a képlet azt a bizonyos nagy számot fogja visszaadni, ami a mi példánkban a 100.
Mi van, ha mást keresünk?
A kapcsos zárójelben felsorolt karakterek természetesen bármi egyéb sorozatra cserélhetők, sőt, nem is kell feltétlenül egy karakteresnek lenniük.
A keresendők lehetnek tartományban is
A kapcsos zárójelben lévő tömbkonstans helyett a képletben hivatkozhatunk
- Egy oszlopos tartományra,
- Névtartományra
- Táblázat oszlopára
Ha a hibakezelést úgy oldjuk meg, hogy a betűket hozzáadjuk a végéhez, lásd:
=MIN(SZÖVEG.TALÁL({„A”;”Á”;”B”;”C”;”D”;”E”;”É”;”F”;”G”;”H”;”I”;”Í”;”J”;”K”;”L”;”M”;”N”;”O”;”Ó”;”Ö”;”Ő”;
„P”;”Q”;”R”;”S”;”T”;”U”;”Ú”;”Ü”;”Ű”;”V”;”W”;”X”;”Y”;”Z”};A2&”AÁBCDEÉFGHIÍJKLMNOÓÖŐPQRSTUÚÜŰVWXYZ”))
akkor már nem tömbképlet és simán is le lehet zárni…
A „nem talált” visszatérési érték meg nyilván a hossz+1 lesz…